JavaparserXXXX乱-为什么 Javaparser 解析结果会乱码?
在 Java 开发中,Javaparser 是一个非常强大的工具,它可以帮助我们解析 Java 代码。有时候我们会遇到解析结果乱码的问题,这给我们的开发带来了很大的困扰。那么,为什么 Javaparser 解析结果会乱码呢?将从以下几个方面进行探讨。
字符编码问题
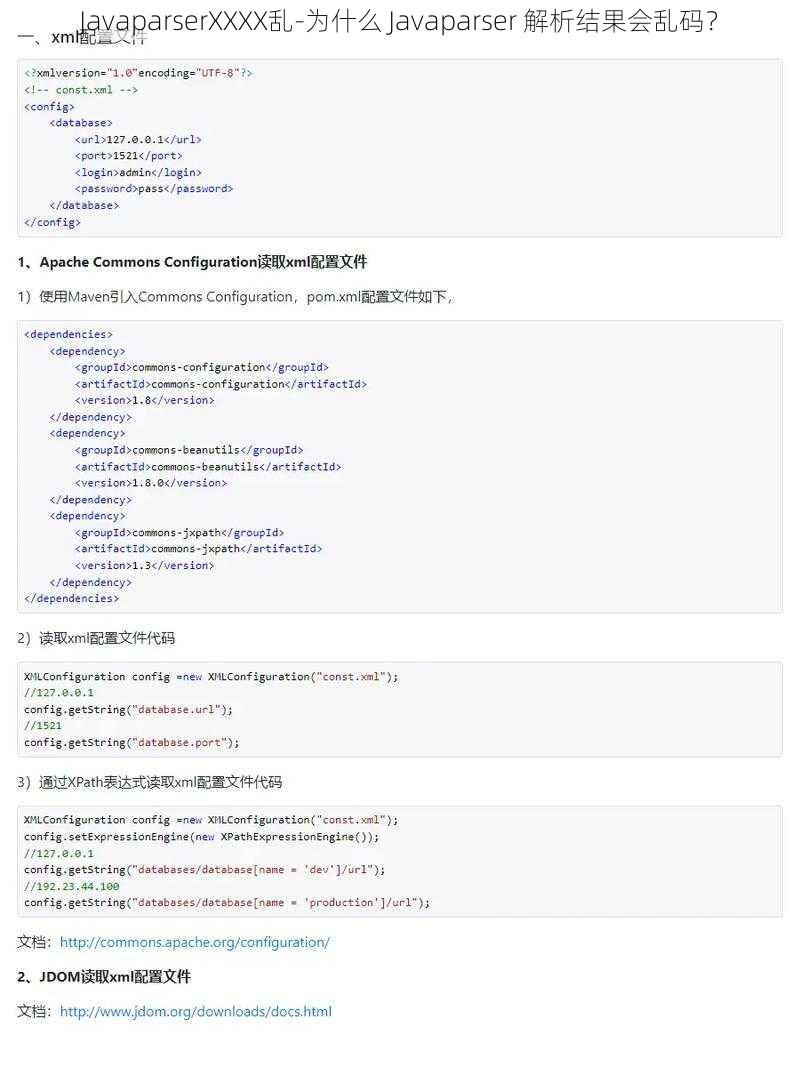
在 Java 中,字符编码是非常重要的。如果我们在解析代码时没有指定正确的字符编码,就可能导致解析结果乱码。例如,我们使用了错误的字符编码来读取文件,或者在解析字符串时没有指定正确的编码,就可能出现乱码。
为了解决这个问题,我们需要确保在解析代码时指定了正确的字符编码。通常,我们可以在读取文件或解析字符串时使用`Charset`来指定字符编码。例如,我们可以使用以下代码来读取一个文件,并指定 UTF-8 编码:
```java
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("file.txt"), "UTF-8"))) {
String line;
while ((line = reader.readLine())!= null) {
// 处理行
}
} catch (IOException e) {
// 处理异常
```
在上面的代码中,我们使用`InputStreamReader`来读取文件,并指定`UTF-8`编码。这样,我们就可以确保读取的文件内容是正确的编码,从而避免乱码问题。
代码注释问题
在 Java 代码中,注释是非常重要的。如果我们在代码中添加了过多的注释,就可能导致解析结果乱码。这是因为注释会影响代码的结构和语义,从而导致解析器无法正确解析代码。
为了解决这个问题,我们需要尽量减少代码中的注释数量。如果必须添加注释,我们可以使用合适的注释风格,并确保注释不会影响代码的结构和语义。
代码风格问题
代码风格也是影响解析结果的一个重要因素。如果我们的代码风格不规范,就可能导致解析器无法正确解析代码。例如,我们使用了不常见的代码缩进方式,或者在代码中添加了过多的空格或制表符,就可能导致解析结果乱码。
为了解决这个问题,我们需要遵循规范的代码风格。例如,我们可以使用空格来缩进代码,而不是使用制表符。我们也需要尽量减少代码中的空格和制表符数量,以避免影响解析结果。
依赖管理问题
在 Java 开发中,依赖管理是非常重要的。如果我们的项目依赖了不正确的库或版本,就可能导致解析结果乱码。这是因为不同的库可能使用了不同的字符编码,或者在解析代码时使用了不同的规则。
为了解决这个问题,我们需要确保项目依赖了正确的库和版本。我们也需要检查项目的依赖树,确保没有依赖了冲突的库或版本。
解析器本身问题
解析器本身也可能存在问题,导致解析结果乱码。这可能是由于解析器的 bug 或者不支持某些特殊的代码结构。
为了解决这个问题,我们可以尝试使用其他的解析器来解析代码。例如,我们可以使用`antlr`来解析特定类型的代码,或者使用其他的第三方解析库。
我们从字符编码、代码注释、代码风格、依赖管理和解析器本身等方面探讨了 Javaparser 解析结果乱码的原因。通过对这些问题的分析,我们可以更好地理解 Java 代码的解析过程,并采取相应的措施来解决解析结果乱码的问题。
在实际开发中,我们需要注意字符编码、代码注释、代码风格等问题,并确保项目依赖了正确的库和版本。如果遇到解析结果乱码的问题,我们可以尝试使用其他的解析器来解析代码,或者检查解析器本身是否存在问题。通过这些措施,我们可以提高 Java 代码的解析效率和准确性,从而更好地支持我们的开发工作。